Chris Padilla/Blog
My passion project! Posts spanning music, art, software, books, and more. Equal parts journal, sketchbook, mixtape, dev diary, and commonplace book.
- Install Pytest through pip.
- When running your tests, call it through the command line:
- Write your test file!
- Playing with shapes and sound, their interaction with one another, is fun unto itself
- Creation is largely puzzle solving. Even playing piano is a finger puzzle
- There's no better way to express love for the world than to try to recapture it as you see it
- Progress, itself, is a joy! Learning an instrument more intimately or refining a line stroke, they all lead to small victories
- There are infinite paths to explore. None right or wrong, only guided by your curiosity and interest
- Photoshop was a required skill for making sites at the time. The main banner and featured videos section were probably made in MS Paint, tough.
- When a new post went up, I simply edited the HTML by hand. I didn't realize many sites had a CMS behind them! I would have been blown away by WordPress
- A missed opportunity: Those posts could have had an RSS feed!
- Tables layouts! Without flex or grid, this was how most developers were creating placing their content/
- No CSS file, really. Any CSS is done inline or with an HTML tag, like the deprecated
<font />and<center />tags. - No JavaScript, ethier! I would have earned a perfect score for performance in my web core vitals.
- Run a DB locally
- Setup our DB Schema through the Models of our application, not in SQL
- Setup migrations for our application to keep the SQL Schema in sync with our models
[Key]is a Data Annotation that lets Entity Framework know that this is our Primary Key in SQL[Required]does as you'd expect. One thing worth noting: to avoid a non-null error, set the Name value in the constructor.- Tolkein's Fellowship of the Ring Wow, the "One does not simply..." meme doesn't actually come up in the book! Nor does "You have my bow...and my axe!"
- Calvin and Hobbes Vol. 1 These strips are so delightfully dynamic! I can't believe I've slept on these.
- Mickey Mouse, Vol. 2: Trapped on Treasure Island A find at Recycled Books in Denton. The adventure strips from the 30's are so wildly detailed!
- I have a few words written through the Books tag on my blog. My favorite this month: Rob Ingles Singing Lord of the Rings
- Rooms With Walls and Windows by Julie Byrne. Beautiful, moody, home grown solo album.
- This Jungle in Gaming Mix on YouTube is a special kind of nostalgic.
- program music II by KASHIWA Daisuke. Is "Music That Could Be in an Anime Movie" a genre?
- Ted Lassoooooo! 💔
- I'm listening to Cartoonist Kayfabe while I draw. Since comics are a solitary experience, it's so fun to hear a couple of pros geek out over them together!
Testing with Pytest
A quick start guide:
python3.7 -m pytest .There's documentation for calling it globally, but I had no luck. Calling it through the same version of python with the -m flag did the trick for me.
import pytest
@pytest.fixture(scope='class')
def my_tests_init(request):
# Set up DB connection here
try:
# Insert any sample date
except Exception as e:
# Handle exceptions
yield # Your tests will happen here
# Tear down: remove sample data from db.
# Close DBPytest will use decorators to add in the functionality needed to interpret your file correctly.
All your tests will live in a class like this one:
@pytest.mark.usefixtures("my_tests_init")
class TestMyClass:
def test_my_method(self):
expected = [{'cool': True}]
result = self.my_class.my_method()
assert result == expectedHere, the decorator ensures the the init method runs before and after these tests.
From there, test methods must start with "test" in the method name.
And you do your thing from there!
Pytest, unlike testing libraries like unittest or Jest in JS, doesn't use assertion methods. Here we just have the assert keyword being used against a boolean expression. Even if we use a reference type, Pytest will know to assert the values of the dictionary or list deeply.
Additionally: If you're not finding what you need from the command line error logs, adding the v flag will give you a closer look, while vv gives you even more details. vv Goes as far to show a git-like comparison, line by line, of what conflicts between your expected and actual results!
Sketchbook No. 5 Down!

Another one down!!
Started off very exercise heavy. These are figure study simplifications of the torso here:

Explored a few animal charicatures:


And then finished the book out with meditative automatic drawing:

My next one is a bigger sketchbook, so I'm excited to have more room to play. :)
Automatic Drawing
Something I'm still learning is to keep more play in all of my creative practices.
Maybe that's surprising to anyone looking in from what I share! But it's true — it's still a challenge to turn off the critical brain when I'm playing an instrument or drawing.
With drawing, I was just doodling and messing with shape at the start. Lately, I've caught myself leaning more towards filling all of my drawing time with exercises and course. If I'm aiming for the 50% rule, I'm really only hitting 25% play. Not entirely a bad thing, but it leaves little room for experimentation and just enjoying the act of drawing.
An experiment I'm trying out to really loosen up is automatic drawing, as demonstrated by Tim Gula here:
The end result is beautiful, but the result isn't really the point. Its meditation for the mind, playing purely with shape, line, and values.
The irony is that, in messing around, a lot of growth happens at the same time: Line quality improves, control over shape develops, and a relaxed brain allows for those periods of focus to be more energized.
Most exciting for me, though, is that when I'm just doodling outside of any coursework, I can shrug off the pressure of it having to be impressive. There's room for experimentation and simply enjoying putting pencil to paper!
I'm trying this out with music too. Lately, I've been spending all my piano and guitar time playing out of books, leaving no time to write or improvise. So now I have a notebook for jotting down improvised chords, melodies, and mini-tunes. Not with the goal of making another album. Just for the space to enjoy sound unto itself.
At the end of the day, sound and line are purpose enough.
Winston Churchill on Painting as a Pastime
I don't always find the inspiration I'm looking for from the bios and stories of full time artists. Those select few who can spend most of their week in the studio. Winston Churchill, who was surprisingly an enthusiastic, self proclaimed hobby painter, can speak much more clearly to the situation of having to find time to be creative in the nooks and crannies of the day.

I've been rattling in my mind all the different reasons I like drawing/piano/guitar/writing music/blogging, and why someone else might like to do them too.
To Churchill, it was no contest comparing painting to more typical leisure activities:
Even at the advanced age of Forty! It would be a sad pity to shuffle or scramble along through one's playtime with golf and bridge, pottering, loitering, shifting from one heel to the other, wondering what on earth to do – as perhaps is the fate of some unhappy beings – when all the while, if you only knew, there is close at hand a wonderful new world of thought and craft, a sunlit garden gleaming with light and colour of which you have the key in your waistcoat pocket. Inexpensive independence, a mobile and perennial pleasure apparatus, new mental food and exercise, the old harmonies and symmetries in an entirely different language, an added interest to every common scene, an occupation for every idle hour, an unceasing voyage of entrancing discovery – these are high prizes.
A particularly sobering passage acknowledges that, as a hobbyist, you won't reach the same great heights of technique as the life-long, full time painters. It's a problem I find myself wrestling with frequently, but Churchill brings it up so matter-of-factly and without much concern:
But if, on the contrary, you are inclined – late in life though it be – to reconnoitre a foreign sphere of limitless extent, then be persuaded that the first quality that is needed is Audacity. There really is no time for the deliberate approach. Two years of drawing-lessons, three years of copying woodcuts, five years of plaster casts – these are for the young. They have enough time to bear. And this thorough grounding is for those who, hearing the call in the morning of their days, are able to make painting their paramount lifelong vocation. The truth and beauty of line and form which by the slightest touch or twist of the brush a real artist imparts to every feature of his design must be founded on long, hard, persevering apprenticeship and a practice so habitual that it has become instinctive. We must not be too ambitious. We cannot aspire to masterpieces. We may content ourselves with a joy ride in a paintbox. And for this Audacity is the only ticket.

It's still worth the pursuit all the same. The rewards for that Audacity are many:
I have written in this way to show how varied are the delights which may be gained by those who enter hopefully and thoughtfully upon the pathway of painting; how enriched they will be in their daily vision, how fortified in their independence, how happy in their leisure. Whether you feel that your soul is pleased by the conceptions or contemplation of harmonies, or that your mind is stimulated by the aspect of magnificent problems, or whether you are content to find fun in trying to observe and depict the jolly things you see, the vistas of possibility are limited only by the shortness of life. Every day you may make progress. Every step may be fruitful. Yet there will stretch out before you an ever-lengthening, ever-ascending, ever-improving path. You know you will never get to the end of the journey. But this, so far from discouraging, only adds to the joy and glory of the climb.
So beautifully said. It all rings true for me:
And why wait? The time to plant a garden is now:
Try it, then, before it is too late and before you mock at me. Try it while there is time to overcome the preliminary difficulties. Learn enough of the language in your prime to open this new literature to your age. Plant a garden in which you can sit when digging days are done. It may be only a small garden, but you will see it grow. Year by year it will bloom and ripen. Year by year it will be better cultivated. The weeds will be cast out. The fruit-trees will be pruned and trained. The flowers will bloom in more beautiful combinations. There will be sunshine there even in the winter-time, and cool shade, and the play of shadow on the pathway in the shining days of June.
While the earlier, the better for overcoming the initial hurdle of learning the vocabulary, it's never too late. Thankfully, the barrier to entry is not technique or years of experience. Just Audacity!

Faber - This One is About Cats
The little rascals! 🐈
Hippo!! 🦛
Happy as a hippo with how this guy turned out!
Not going to lie, I can see the difference of spending nearly 6 months on lines with the Proko course!

MVC in ASP.NET Core
This week's edition of ASP.NET adventures: kick starting an MVC app with ASP.NET Core!
On the front-end side of things: Two things that make this a really delightful and smooth process are Razor Pages and Tag Helpers.
My MVC experience up to this point has been with templating engines in Express. What they do well is make it dead simple to get data into the template. The limitation is flexibility and reactivity. (Especially coming from working mostly in React.)
ASP.NET MVC apps have a really nice in between through these two tools.
I'll show the setup with Models and Controllers first, then on to views in action!
(Code samples and all of my info here are coming from this great introductory video to MVC in ASP.NET Core 6)
Models
Here's a look at the model I'm using:
using System;
using System.ComponentModel;
using System.ComponentModel.DataAnnotations;
namespace BulkyBookWebDotNet6MVC.Models
{
public class Category
{
[Key]
public int Id { get; set; }
[Required]
public string Name { get; set; }
[DisplayName("Display Order")]
[Range(1, 100, ErrorMessage = "Display Order must be between 1 and 100")]
public int DisplayOrder { get; set; }
public DateTime CreatedDateTime { get; set; } = DateTime.Now;
}
}Nothing fancy! The code in square brackets are used by Entity Framework for field validation. DisplayName will affect what's rendered in the view, for example. Otherwise DisplayOrder would be the defaut.
Controller
Setting up controllers is a straight-shot. Grab what's needed from the database and send it the view.
// GET: /<controller>/
public IActionResult Edit(int? id)
{
if (id == null || id == 0)
{
return NotFound();
}
var CategoryFromDb = _db.CategorySet.Find(id);
//var CategoryFromDb = _db.CategorySet.FirstOrDefault(u=>u.Id == id);
//var CategoryFromDb = _db.CategorySet.SingleOrDefault(u=>u.Id == id);
if (CategoryFromDb == null)
{
return NotFound();
}
return View(CategoryFromDb);
}
// Post: /<controller>/
[HttpPost]
[ValidateAntiForgeryToken]
public IActionResult Edit(Category obj)
{
if (obj.Name == obj.DisplayOrder.ToString())
{
ModelState.AddModelError("name", "Display order cannot match the name.");
}
if (ModelState.IsValid)
{
_db.CategorySet.Update(obj);
_db.SaveChanges();
TempData["success"] = "Category updated successfully";
return RedirectToAction("Index");
}
return View(obj);
}View
Here's an example of a "Create Category" page for an app:
@model Category
<h1>Create</h1>
<form method="post">
<div class="border p-3 mt-4">
<h2 class="text-primary">Create Category</h2>
<div asp-validation-summary="All"></div>
<div class="row pb-2">
<label asp-for="Name"></label>
<input asp-for="Name" class="form-control" />
<span class="text-danger">@Html.ValidationMessageFor(m => m.Name)</span>
</div>
<div class="row pb-2">
<label asp-for="DisplayOrder"></label>
<input asp-for="DisplayOrder" class="form-control" />
<span class="text-danger">@Html.ValidationMessageFor(m => m.DisplayOrder)</span>
</div>
<button type="submit" class="btn btn-primary" style="width: 150px;">Create</button>
<a asp-controller="Category" asp-action="Index" class="btn btn-secondary" style="width: 150px;">
Back To List
</a>
</div>
</form>
@section Scripts{
@{
<partial name="_ValidationScriptsPartial" />
}
}At the top, we're bringing in my Category model with @model Category. The controller takes care of sending this to the view both on GET and POST requests:
For the most part, I'm just writing regular html. If I needed to include anything from the model, I could throw @Category.Name anywhere and it will render to the page. Any C# that I wanted to write just requires the @ symbol.
Tag Helpers
The killer part of the example for me are the asp- attributes. These are Tag Helpers that inject a lot of functionality automatically.
Take a look at the name field:
<div class="row pb-2">
<label asp-for="Name"></label>
<input asp-for="Name" class="form-control" />
<span class="text-danger">@Html.ValidationMessageFor(m => m.Name)</span>
</div>asp-for on the label and input will know to populate the name input with the value from name, as well as pull from it when the form is submitted. Also included is client side validation automatically. When an error is found, the message is then passed to the @Html.ValidationMessageFor(m => m.Name)
That's it! It's a fair bit of magic, but it saves a lot of code that would normally be done by hand in JavaScript, or requiring a heavy library.
Learning the Neck on Guitar
Guitar has hands down been the hardest instrument I've played as far as getting familiar with the notes.
Saxophone, admittedly, is one of the easiest. You really only have to learn 20 different finger combinations, and then you know most of the instrument.
Piano is even easier!! You learn 12 notes and you can apply that to all 88 keys. Maybe you could say it's more like 24, since you're also reading bass clef.
Here's the thing about those instruments: They are two dimensional. You play up the piano, and gradually go up. Same with sax and most wind instruments.
Guitar, though, is three dimensional. You can go up the instrument by following a string up or by hopping to another string.
Wicked.
If you're like me, you can go surprisingly far on guitar without knowing too many notes, too. A trained ear and know that a scale is a series of whole and half steps does wonders.
But! It doesn't take me far enough. So here's how I'm going about actually learning where every single note is on this instrument:
1. Reading Sheet Music over tabs.
For bettor or worse, I learned to read music from the page.
If you're learning and you don't already read music, I'm not sure it's that necessary depending on what you want to do. If you already do, making the notes visual is a pretty great first step
2. Barre Chords
A two for one: Once you can play barre chords, there's no better way to get familiar with the thickest two strings than with playing this across the instrument.
3. Hardcore Memorization
The least sexy, but the most effective. A professor of mine from undergrad, while learning Portuguese, said it plainly: "There's a lot of romanticizing around immersive learning. While that's all fine and well, nothing beats buying a dictionary and memorizing the words."
The point isn't one is better than the other, you need both, but guitar players (especially me) can be guilty of only playing and putting off learning the notes through a more rote approach.
Thankfully, it's infinitely easier in 2023 with apps and online tools.
At the risk of this blog sounding like a sponsored post: My favorite is Justin Guitar's Note Finder App. It's what you'd expect and a little more: Finding the note on a nice GUI, an option to try and identify what note is being shown. It even feels like a game, so it can be addictive to study the neck this way.
4. Triads
My next step is moving on to playing triads to bridge the theory to actual music making. More improv on it coming soon. 😁
250 Box Challenge and Repetition
I'm doing the 250 box challenge right now. It's the namesake for the website drawabox.com.
The gist: You draw lots of boxes in 3 point perspective. In pen. And you extend your lines at the end to check that the points converge towards a vanishing point.
Brutal.
The exercise looks like this:
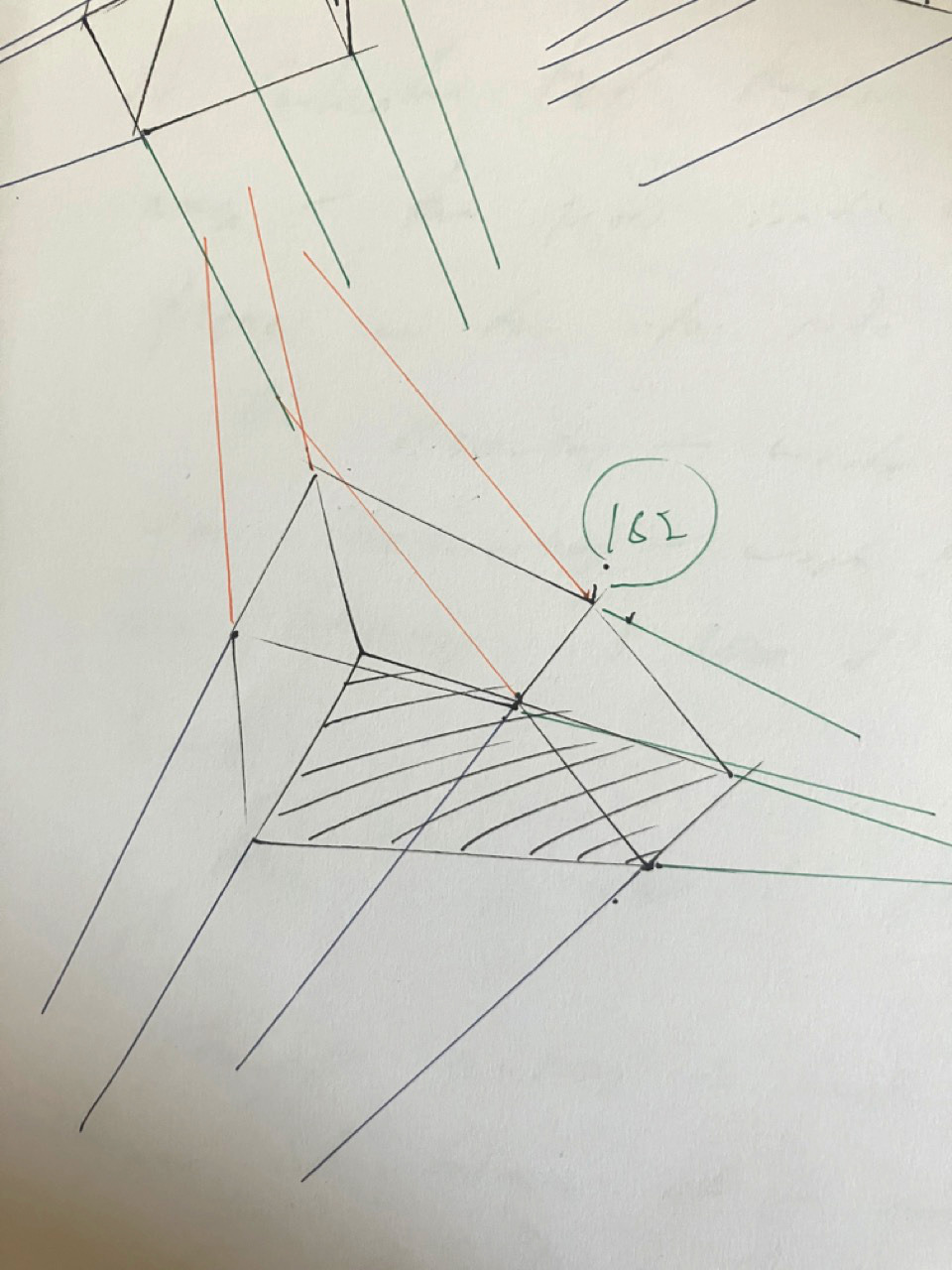
The point is to get familiar with perspective. And every now and then I stop and ask "am I doing this wrong? Are there any tips? Am I just not looking at it the wrong way. Maybe if I find another guide..." It's a question I've had for most art. If I find the right strategy, I'll just know how to do the thing.
But, in my experience so far, there is just some intuition that comes from repetition. There's no real strategy aside from "do it again, but try another approach."
On a practical level, what helps me is to plot a dot for where I think a line will go and then ghost it like crazy. I'll intentionally plot one that I know is parallel as a reference if I'm really unsure.
But, for the most part, it's like learning a sport or an instrument: the more you do it, the more your brain will learn the fine-motor control of what you're trying to do.
That's what really struck me! Just like I have to practice scales, I have to warm up on drawing lines.
I kind of wish the challenge was called "Draw 250 boxes (mostly badly!)" since that's the intention behind it!
All this to say: Art, especially at the beginning, is just as much a physical skill as it is a design skill.
My First Website from 2005

Like many folks born in the early 90s, I grew up with the web. You could say we both grew up alongside each other! I was right on that edge of entering elementary school just as the internet became a household utility.
I was coding my first few webpages at 8 years old, which is wild to think about looking back. I played lots of Neopets at the peak of its heyday. The platform exposed a way for player's to add custom HTML for their shop pages and profiles. With the help of some kid-friendly HTML resources, I was able to add midis, custom cursors, and all sorts of Geocities-era site features!
Fast forward into my teens, on the other side of the early rise in Youtube's popularity. I took up video making and sketch writing for fun. And most of the "pros" (at least, the larger channels) had their own websites.
I was already drawing comics at the time, too. I would pass a four-panel strip around and share them with friends in class. Like a daily syndication, but on notebook paper and in No.2 pencil. I wasn't aware of the rise of webcomics online at the time, but it occurred to me all the same that having a home for those doodles and videos would be a pretty neat idea.
And so, moomoofilms.com was born.
Unfortunately, most of the site has been lost to time. The HTML was coded directly on my hosting service's platform, which shut down years ago. I still have the videos on a hard drive (too juvenile to share publicly, but endearing all the same!) The comics are gone, maybe in a folder back in my parents' attic. And a few small technical experiments and widgets have been lost too. (Moral of the story: Back up your files!)
Thanks to the Way Back Machine, I was able to recover the landing page!
Technical Comparisons
A few fun observations comparing this to modern websites:
<table border="0" cellpadding="2" cellspacing="1" style="border-collapse:" width="505" bordercolor="#666666" valign="top">
<tr>
<td width="503" colspan="2" background="./assets/news.jpeg">
<b><font size="2">Happy Belated New Year! - 1/20/08</font></b>
</td>
</tr>
<tr>
<td width="51">
<img border="0" src="./assets/aimbagelboyfield.jpeg" width="50" height="50"></font>
</td>
<td width="451">
<p align="left">
Good News, everyone!
...
</p>
</td>
</tr>
</table>The Good Ol' Days
My site pre-dated widespread social media. If you wanted an online profile, you had a few options like Livejournal, Blogger, WordPress, etc. Or you did what I did and rolled up your sleeves to put the HTML together.
That lent the internet to so much customization and ownership! Compare that to the cookie-cutter profiles across social media now.
Making sites was a unique, widespread way for a broad audience to be introduced to programming. (Calling HTML programming is a stretch to some, but I say it counts!) I know plenty of developers that got their start customizing MySpace, Tumblr, and WordPress pages.
Today, It's great that anyone can make a profile on any platform and start sharing. I'm nostalgic, though, for the inherent ownership and creativity that was baked into the early days of the web.
Especially for kids! In passing, I think about how my future-kids will develop their own technical literacy. Impossible to say now, things continue to change so quickly. But, so long as there are platforms for them to get their hands dirty, play, and really mess around with what's under the hood, I'm sure there will be a way.
Calvin in the Tree House

Study after Bill Watterson.
I've been reading Calvin and Hobbes. I grew up collecting lots of Garfield, but man, these comics are just so dynamic for a newspaper strip! 🐯
Dvorak — New World Finale
So TRIUMPHANT! 🌅 💪
Database Setup and Migrations for Microsoft SQL Server and ASP.NET Core MVC
I know this is old news at this point, but using Microsoft products on Mac (let alone an M1 machine!) is a wild concept to me! It's in the same vein as Superman & Batman in the same movie, or Mario and Sonic in the same game.
I'm getting familiar with ASP.NET Core 6.0 MVC. I've been able to get things up and running with primarily native solutions, much to my surprise! There are a few different paths I've had to take to get all the way, though.
The tl;dr: For .NET, favor the dotnet CLI over the Visual Studio GUI. For SQL, Docker is your friend.
To expand on it, here's how I handled getting my local environment set up to run a local Microsoft SQL Server for my web app:
Overview
The ultimate goal here is:
Here we go!
Running Microsoft SQL Server Locally
The solution on Windows for interacting with the Database is Microsoft's SQL Server Management Studio (SSMS). For Mac and Linux, we'll have to opt for Azure Data Studio.
That takes care of the GUI.
For running a server, this guide gets you most of the way there.
The caveat is that on M1, there's not great support for the image mcr.microsoft.com/mssql/server:2022-latest.
Instead, grab the Azure image:
$ docker run -e "ACCEPT_EULA=Y" -e "MSSQL_SA_PASSWORD=YOURGENERATEDPASSWORD" -p 1433:1433 -d mcr.microsoft.com/azure-sql-edge:latestThe -e "ACCEPT_EULA=Y" is important for accepting the terms and conditions before running.
The rest of the guide will take you through connecting to Azure Data Studio!
Creating Models
Assuming you already have an app template running, we'll add a new Model called "Book" to our project:
// Book.cs
using System;
using System.ComponentModel.DataAnnotations;
namespace LibraryMVC.Models
{
public class Book
{
[Key]
public int Id { get; set; }
[Required]
public string Name { get; set; }
public int isbn { get; set; }
public DateTime CreatedDateTime { get; set; } = DateTime.Now;
public Category(string name)
{
Name = name;
}
}
}A quick run down of some interesting points:
That's all there is to setting up the Schema!
Migrations
If you're used to MongoDB, this is where you would call it a day for setting up the schema. MongoDB doesn't require any enforced schema at the database level.
With SQL, however, we do have more setup to do there.
The excellent thing about this approach, coming from Express and Mongo, is that largely, the source of truth is still in our application. We'll simply setup a migration for SQL to mirror the schema from our Model.
A deeper Migrations Overview from MS is available on their site. For us, let's get into the quick setup:
First, ensure you have the dotnet CLI installed.
We'll use it to install the Entity Framework tool globally:
dotnet tool install --global dotnet-ef --version 6.0.16With that, you can then run this command to migrate:
dotnet ef migrations add AddBookToDatabaseAddBookToDatabase is what the migration will be named. You can call it whatever you like.
You may need to install extra Nuget packages before the command goes through:
Your startup project 'LibraryMVC' doesn't reference Microsoft.EntityFrameworkCore.Design. This package is required for the Entity Framework Core Tools to work. Ensure your startup project is correct, install the package, and try again.With the SQL server connected, Entity Framework will look at the models in your app, compare what's in the DB, and create the DB with appropriate tables and columns based on your models directory.
To verify all worked, you can check Azure Data Studio for the data, and look for a "Migrations" folder at the root of your application.
And that's it! All set to fill this library up with books! 📚
The Haps - June 2023
Summer time!!!
Blogging & Dev
Taking a slower pace with blogging, but still sharing my adventures in C# and .NET!
You can catch up with my tech projects through the Tech tag on my blog.
Music
I released Forest a while back! An experiment in playing with a few sounds from Ocarina of Time and Chrono Trigger!

I'm digging deep into learning finger style guitar. My favorite so far was this cowboy waltz I improvised on my new acoustic.
You can see what I've shared so far through the Music tag on my blog. I'm also sharing recordings on Instagram.
Drawing

I finished my fourth sketch book! I'm starting to not treat them as precious and am really drawing loosely in them. It's great, very liberating!
My routine at the moment is studying other artists, drawing from imagination, and doing perspective / figure drawing exercises. Both from Proko and drawabox.
You can see what I've made so far through the Art tag on my blog. I'm also sharing drawings on Instagram.
Words and Sounds
📚
🎧
📺
Life
It's hot. I'm cold blooded. So I'm in my element! ☀️
Had my folks visit for Mother's day!! We had a good time exploring a few museums in Dallas and eating good food.

👋
Turkey Groom
"Draw everyday," I said! "It will be a great way to enrich your memories!"
Yet, I couldn't tell you why I sketched a wedding cake with a turkey groom last week. 🦃
